
Computer graphics is mostly associated with the creation of artificial images that resemble real photographs as close as possible. However, realistic representations usually contain more information than necessary to transmit intended information. Abstract images can be used to convey information more effectively. The field of non-photorealistic rendering focuses on the automatic creation of these expressive illustrations, often inspired by the work of real artists.
The evaluation of abstract representations created by such algorithms is challenging and often very subjective. For drawing styles working on distinct rendering primitives (e.g., points and lines), choosing the number of drawing primitives always involves trade-offs between quality and computation time. In our presented work, we create a model to predict the perceived quality of such illustrations depending on the number of drawing primitives, giving the user a quantitative basis for his decisions.



Since it is difficult to find objective functions that quantify the visual quality of such illustrations, we propose an approach to derive perceptual models from a user study. However, it is difficult to directly assign an absolute quality value to an abstract visual representation. The reason for this is that the same values might be understood differently from person to person, and the range of values can differ between subjects as well. Therefore we take an alternative approach by presenting subjects with two different illustrations together with the task of performing relative judgments. Using this comparative data, we can employ a paired comparison model to reconstruct absolute quality values. In the following, we show the reconstructed models for stippling (drawing only using points).
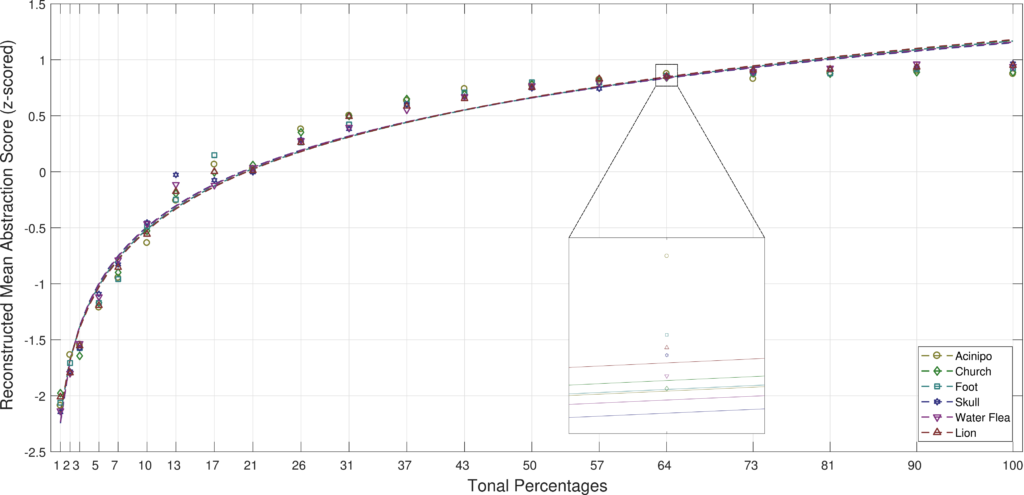
A logarithmic relationship between perceived quality and number of drawing elements was observed. Therefore we propose using a logarithmic regression model. The models for each different input are almost identical, indicating that the perceived quality is independent of the content of the input. To make models from different algorithms or parameter settings directly comparable, they have to share a common scale. For this purpose, we conducted a second form of user studies that directly compared the result from different methods. As an example, we compared results created for stippling using a constant and variable point size settings. In the next following, we show the reconstructed model for constant (Model factor 1) and variable point size stippling (Model factor 2 and 3, higher values indicating higher spread between point sizes).
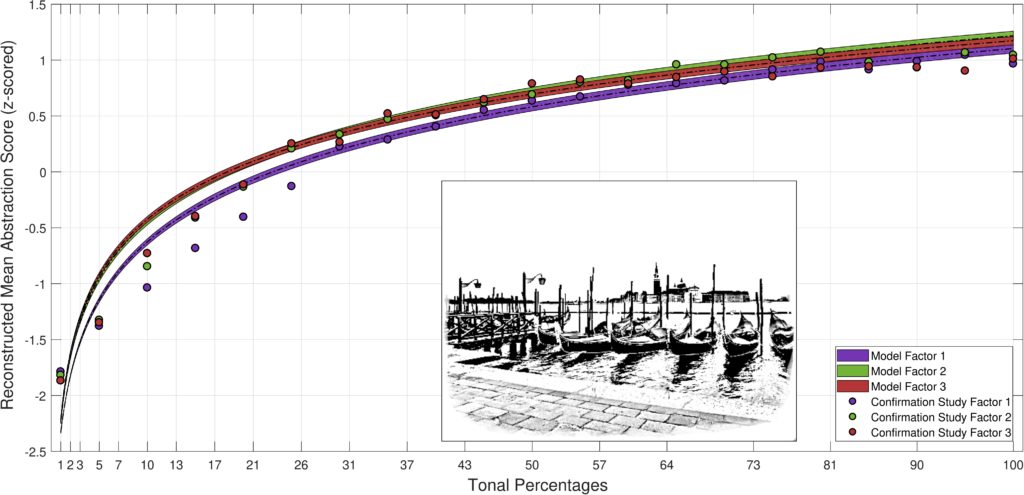
By using variable point sizes (Model factor 2 and 3) depending on the local grayscale value we can save a large number of points in darker regions by simply increasing their size, thereby not only boosting the visual contrast but also allowing better placement of the saved points. When looking at any of the variable point size models, we can see that this assumption holds. The scores increase more rapidly compared to the model for constant point size, while the differences become smaller at higher tonal percentages. This latter observation can be explained by the level of detail retained through a large number of small points at higher tonal percentages, which makes differentiation more difficult. Not only this, but we can now also objectively quantify the “gains” by using a variable point size model over a constant one: Between Model factor 1 and 3, a 17.5% reduction of primitives required for the same visual quality can be observed.
We showed that this presented approach also holds for a different drawing primitive with small lines, however for future work we want to include even more abstraction methods, including those working on more spacious drawing primitives, such as brush strokes. Here problems such as overlap arise that have to be addressed.
For more information about this work: https://doi.org/10.1145/3301414